For many pieces of code we write as SW engineers, we need to understand the efficiency of that code. However we don’t usually rigorously and mathematically prove the complexity of algorithms we consider. Instead, we use our intuition for the complexity at hand, and “T-shirt size” thinking in order to determine algorithm’s “cost”. On occasion, especially when interviewing candidates, I see this intuition is somewhat lacking, so I put together a list of the common complexity “classes”, with the intuition behind them. Of course they are all eventually based on the “Big O” notation, but it is important to be able to think about them intuitively.
Disclaimer 1: We will be focusing on how many times the algorithm “visits” parts of the input, and neglect what it does on each “visit”. In the real world you cannot neglect that, and you need to be efficient on both the asymptotic behavior (big O) and on the constants. Moreover, on small inputs it can be the case that an asymptotically inefficient algorithm is used, for example because it is simpler and fast enough for the job.
Disclaimer 2: I am making some heavy compromises here on the rigorousness of the definitions, but for the goal of increasing intuition, please accept some loss of mathematical accuracy.
Complexity classes – Intuition
O(1) or “constant time”
The name says it. Anything you can do in constant time, meaning that the time, or number of operations is not growing as the input grows. Examples: Array cell access. However large is the array, you can access a cell by calculating its address (cell number times the element size) and address that memory cell directly. You will do the exact same operation no matter the size of the array.
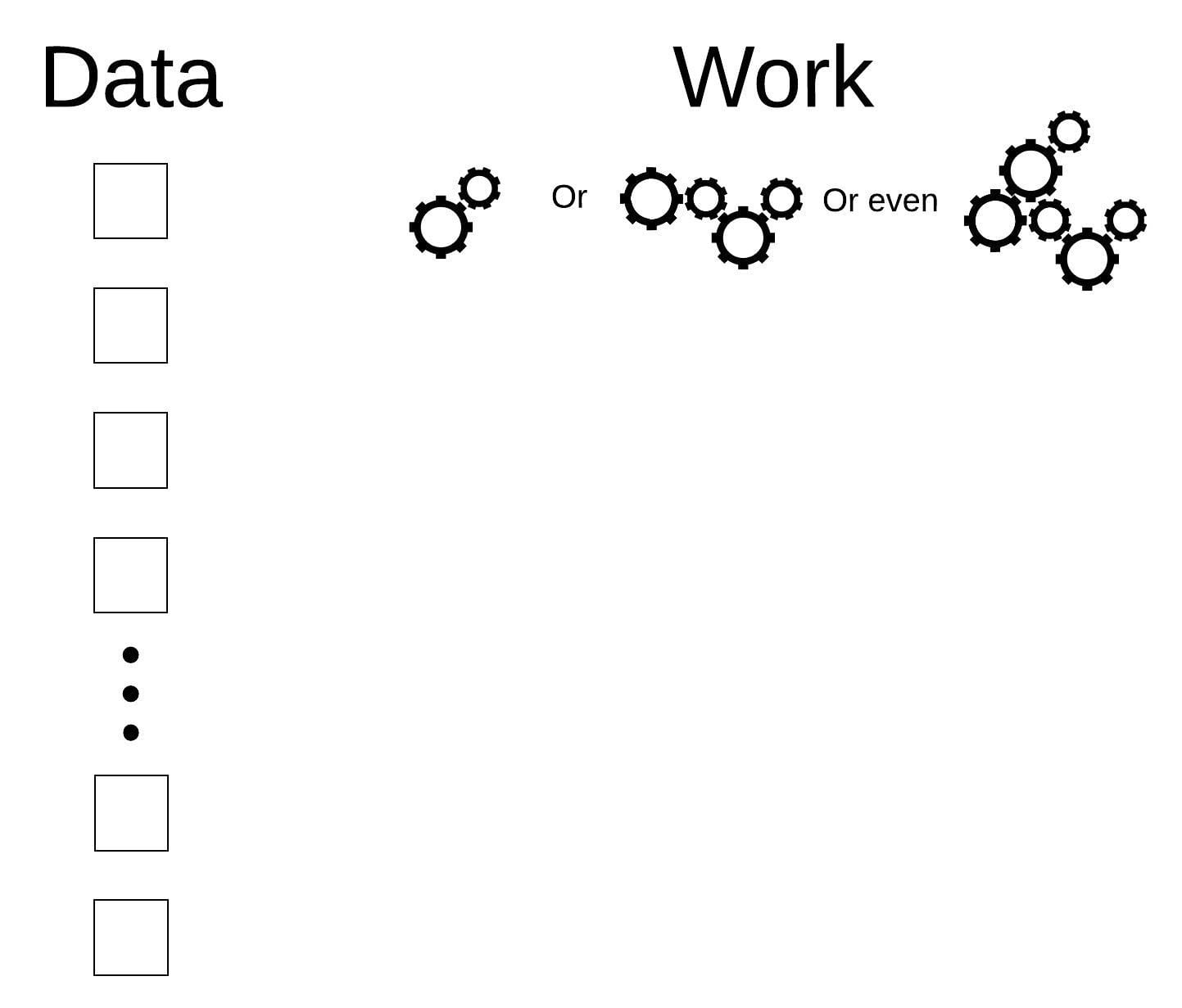
O(log N) or “logarithmic time”
If on every “progress step” you make on your way to your target you can “eliminate” half of the remaining work, you are doing work in logarithmic time. Examples: Binary Tree traversal and Binary Search in a sorted array. In both those examples, on every step you make you can save a lot of work for the following step, since you have information that lets you cut the input to the next step by half. This extra knowledge (the tree structure, the array being sorted) is why, intuitively, you can “save energy” and avoid going over all the elements. Putting it the other way around, if you are asked to solve something in logarithmic time, and you think it requires knowledge on the entire input, ask yourself what energy was spent by someone else to make this possible.
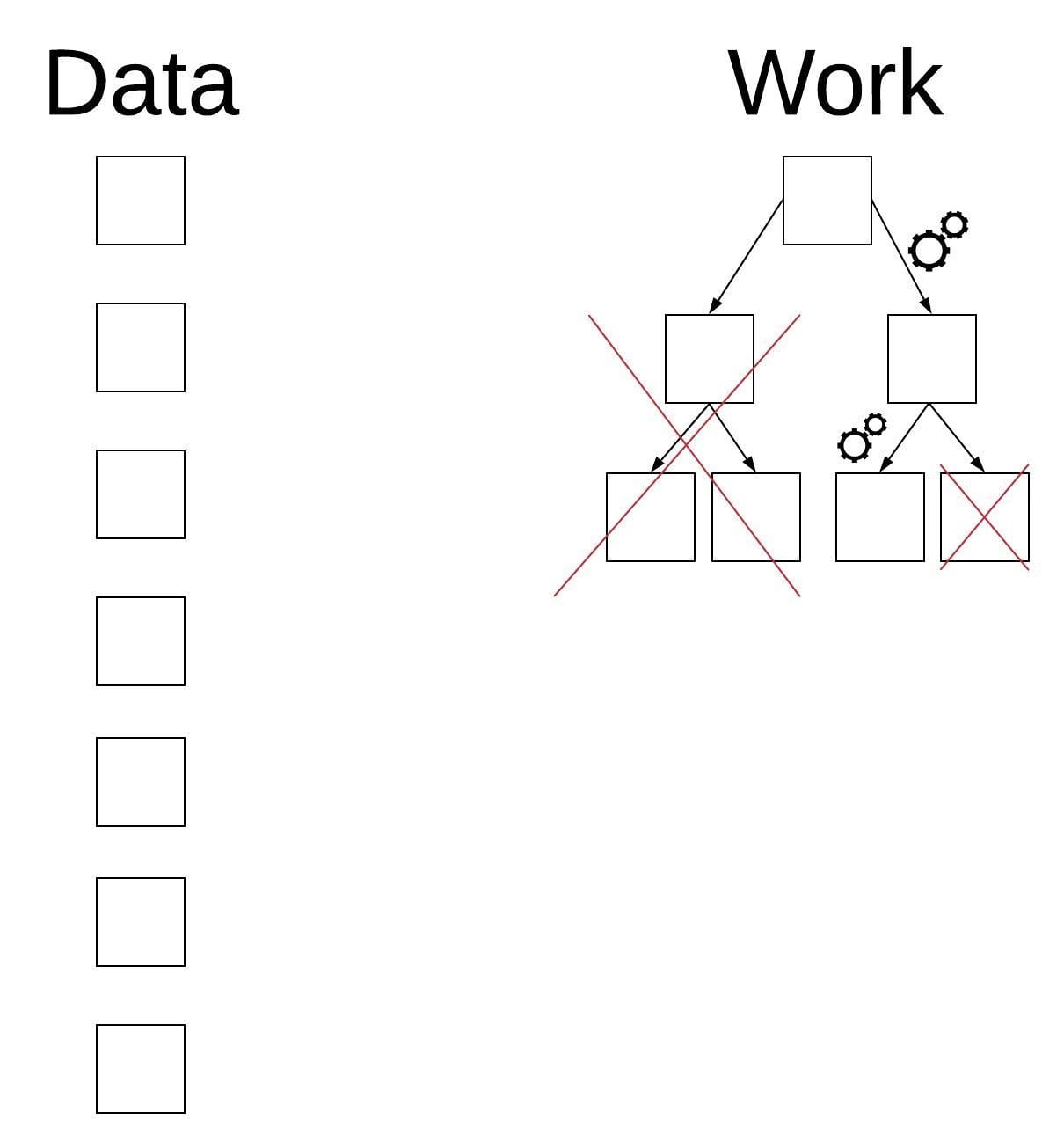
O(N) or “Linear Time”
If you need to traverse the whole input, for a constant number of times, you get linear complexity. It could be more than once, but the number of times must not grow with the input, it must remain a constant number of times. So, you cannot avoid running through all the elements, but on the other hand it is sufficient to do it a constant number. Examples: Searching an array or a list for all the appearances of the number “3”, or efficiently finding the maximal value in a given array or a given list.

O(NlogN)
I don’t have a great intuition for that one. You no longer do constant-time work for each element like in linear complexity. Now, for each element you do an amount of work that grows with the input size, even if as slowly as logN. There is an important insight about logN (Thanks Dr. Omer Lev) – it grows very slowly. Let’s imagine sorting one million items. Binary log(1,000,000) is less than 20. Binary log() of the number of particles in the universe is less than 268! So it is worse than linear complexity, but not by much.
Example: in Tree Sort, you know that adding a member to a (balanced) tree is logN work, and you have to do that for your N elements, so you end up with O(NlogN). However that is not a very good complexity intuition, it is a calculation. Sorry.
O(N^2) or “Quadratic Time”
My intuition for the O(N^2) complexity “class” is: for every element you have, you do something with most of the other elements. This intuition is dangerously close to that of O(NlogN) since I had to use the word “most”, but I would be bold enough to say that in the case of O(NlogN) algorithms, it will be very apparent that the multiplicand is behaving like logN, which is not “most”, not like a “N” or even close to it.
Let’s linger a little bit more on this “most” thing and why we have to take it with a grain of salt. Let’s look at the classic example to show what “most” means – Bubble Sort. In the worst case, the array is reversely sorted so you will have to “bubble up” each element across all the elements remaining from previous operations. So the number of operations is proportional to an arithmetic series summation given by (N*(N-1))/2. The dominant element here is the N^2 element so with a growing number of elements it will dominate the result and you have O(N^2).
Intuitively, for each of the elements we start a bubble-up process with, we have 1 less element to work with compared to the previous bubble-up run, but that does not save us from ending up with O(N^2). This is because, saying loosely, the diminish in the amount of work for each element is too small to “save us” from ending up with O(N^2).

O(N^a) or “Polynomial Time”
Although you may see ‘a’ being different than ‘2’, for example in Matrix multiplication when we look at O(N^3), I think the discussion on O(N^2) covers the rest of the polynomial complexities.
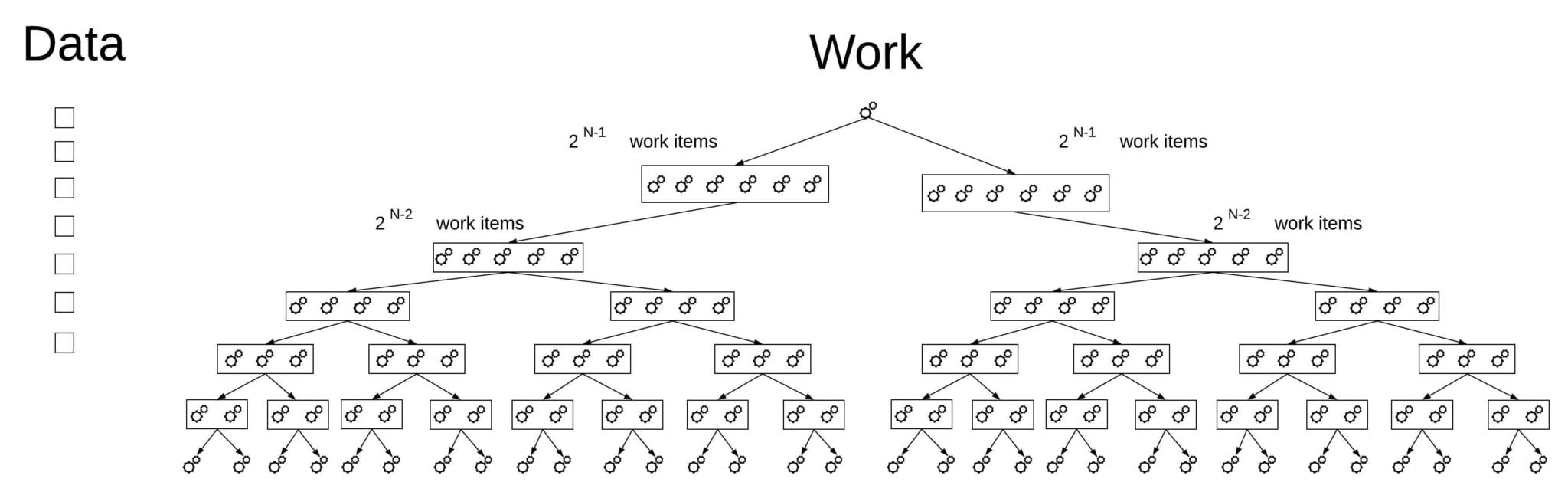
O(2^N) or “Exponential Time”
if you find yourself going over all the combinations/subsets of the given input’s elements, you are dealing with an exponential time algorithm. Example: the (integer) Knapsack Problem. You have no choice but to try all the combinations of items, so you end up with an amount of work exponential to the number of items. Another Example: find all the subsets of a set of elements. This is almost tautology. For a set with N elements, there are 2^N subsets.
One example where a finer intuition may be required is the Hanoi Towers problem, since it may not be apparent at first sight that what we are doing is going over all the combinations. Because of that, let’s refine our intuition: if the algorithm is built by doing constant-time work for an item, and then continue to solve two identical problems with the rest of the elements, you are going to get an exponential complexity. In the Hanoi Towers example, on each step we single out one element and then solve 2 Hanoi Towers problem on the remaining items. You can imagine this as creating a full binary tree, with each node representing a recursive function call (see the diagram below). A full binary tree with height N has 2^N leaves, and more nodes than that, so you definitely got yourself an exponential algorithm.
It’s interesting to take this refined complexity intuition and see if can be somehow unified with the former, “all combinations” intuition. If we take the “find all subsets” problem, an algorithm can say:
Take an element “out”. Now, create all the subsets possible from the remaining N-1 items (notice this is recursive). Now create more subsets by attaching our singled-out element to all the subsets created by the N-1 elements.
So, for each element, we need to solve a problem of size 2^(N-1) to get all the subsets of the remaining N-1 items, and then do 2^(N-1) actions to attach the singled-out element to the subsets created recursively. So yes, the “all combinations” thinking maps nicely into the second intuition presented above.
See a nice test case on O(2^N) at the end of this post.
O(N!) or “Factorial Time”
If you find yourself examining all the permutations of the input’s elements, you are dealing with a Factorial complexity algorithm. As for the Intuitive Complexity of this, notice that asking for permutations adds a notion of order to the “sets”, so you get many more results than in subsets. Example: the brute-force solution to The Travelling Salesman problem, trying to naively find the best route between several towns by checking them all. For a starting point, you have to check all the combinations of the remaining towns, and there is importance to their order, unlike the subset problem described above.
O(N^N) or “End of Time”
I am kidding, it’s not named like that. But, it doesn’t need a name, although it is also a kind of an “exponential” complexity with a growing base (N) instead of a fixed base (2). If you got to the constant-based exponent O(2^N), you are in a very bad shape already. So, that is just a “super bad” exponential complexity.
A nice Case Study
What is the complexity of calculating the Nth Fibonacci Number? Since we can do that with a single run on all the numbers from 0 to N, it has to be Liner Complexity, right? Well, it can be. However many people will solve it in the recursive way:
int fibonacci(unsigned int N)
{
if(0 == N) return 0;
if(1 == N) return 1;
//Else
return fibonacci(N – 1) + fibonacci(N – 2);
}
Is that liner? No! In each stage in the recursion, this code will span all the possible combinations for the remaining numbers, doing an exponentially growing amount of work. if you look at the illustration below, you will see what is happening. Some of the calculations are done repeatedly, “wasting energy”. I have colored repeated calculations, each one with a unique color.
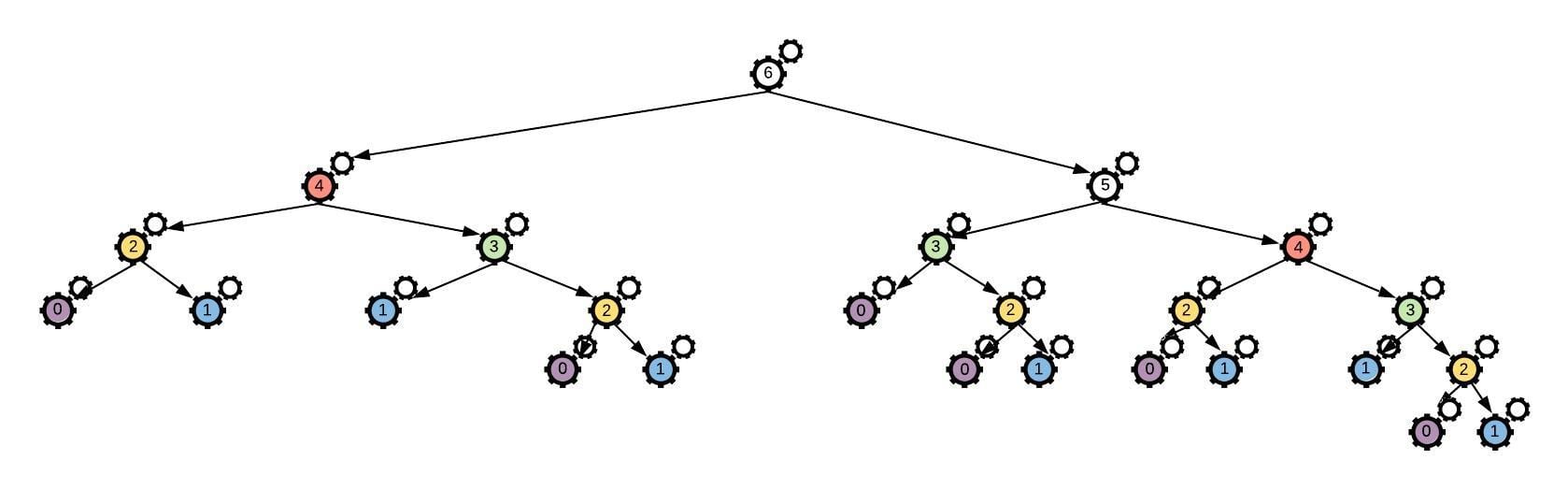
So, the implementation details can definitely mess things up, and at times can mislead our inner sense of intuition for complexity. Here is the Linear-time solution:
int fibonacci(unsigned int N)
{
if(0 == N) return 0;
if(1 == N) return 1;
int N_minus_2 = 0;
int N_minus_1 = 1;
int accumulator = N_minus_1 + N_minus_2;
int i ;
//We already have the first 2 elements.
for(i = 0; i < (N-2); ++i)
{
//Prepare for the next N
N_minus_2 = N_minus_1;
N_minus_1 = accumulator;
//Sum the two previous results
accumulator = N_minus_1 + N_minus_2;
}
return accumulator;
}
It is not as Handsome as the recursive solution, but it is linear and it will also not fill the stack with function call frames.
14 Comments
аренда яхта сейшелы go now
katamaran mieten sudfrankreich european yachts
https://avenue17.ru/
Would you like to have a sip of my coffee? http://tiny.cc/gz35vz
номера австралии continent telecom
hentai420
wepron
According to J. Carpenter’s site, Tor2Door and other dark web markets often have to modify their onion addresses because of DDoS attacks and to avoid being blacklisted by services and antiviruses.
wg680q
Matchless topic
_ _ _ _ _ _ _ _ _ _ _
aliexpress promo code $60
Greetings! Very useful advice in this particular article! Its the little changes that will make the biggest changes. Thanks for sharing!
ChatCrypto is building a high performance AI Bot which is CHATGPT of CRYPTO.
We are launching the Worlds first deflationary Artificial Intelligence token (CHATCRYPTOTOKEN) which will be used as a payment gateway to license
Join the Chatcrypto community today with peace of mind and happiness, as registering for an account will reward you with 1600 Chatcrypto tokens (CCAIT) for free
Project link https://bit.ly/41Fp0jc
Not only that, for every person you refer to Chatcrypto, you’ll earn an additional 1600 tokens for free.
q1w2e19z
ChatCrypto is building a high performance AI Bot which is CHATGPT of CRYPTO.
We are launching the Worlds first deflationary Artificial Intelligence token (CHATCRYPTOTOKEN) which will be used as a payment gateway to license
Be rest assured and happy to be part of Chatcrypto family as signing up would give you free 1600 chatcrypto tokens(CCAIT)
Project link https://bit.ly/41Fp0jc
and with every referral you refer to Chatcrypto, you earn extra 1600 tokens for free.
q1w2e19z
ChatCrypto is building a high performance AI Bot which is CHATGPT of CRYPTO.
We are launching the Worlds first deflationary Artificial Intelligence token (CHATCRYPTOTOKEN) which will be used as a payment gateway to license
Join the Chatcrypto community today with peace of mind and happiness, as registering for an account will reward you with 1600 Chatcrypto tokens (CCAIT) for free
Project link https://bit.ly/41Fp0jc
Not only that, for every person you refer to Chatcrypto, you’ll earn an additional 1600 tokens for free.
q1w2e19z