In the first part of this post, a “classic” example of Polymorphism-like code in C was discussed. Let’s look at some production code I had a chance to refactor. After the refctoring, the code looks like another step forward towards the Polymorphic behavior of real OOP languages. For obvious reasons, I have modified the example such that it is more focused.
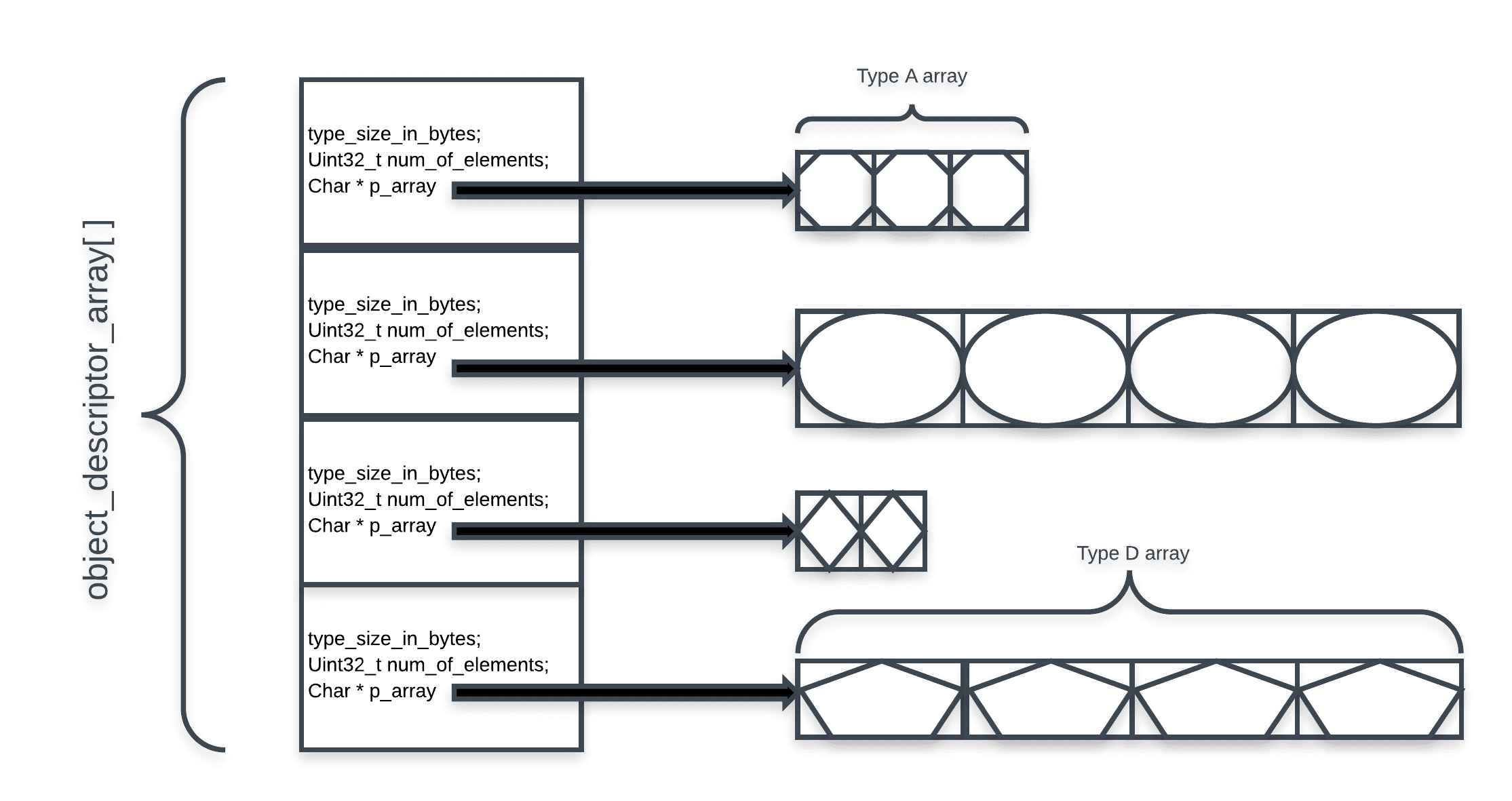
The original code used an array of object types. For each one, an array of instances was allocated. The “Type structure” looked like that:
typedef struct
{
unsigned int type_size_in_bytes;
unsigned int num_of_elements;
// This will point to the allocated array of instances
char * p_array;
}TYPE_DESCRIPTOR;
And, there was an array of those “descriptor” objects plus an enum to enumerate the different types:
typedef enum
{
OBJECT_TYPE_A = 0,
OBJECT_TYPE_B,
// And so on, types C, D, E, etc
OBJECT_TYPE_Z,
//This must not used as a type,
//it simply signifies how many types we have
NUM_OF_TYPES
}OBJECT_TYPES;
TYPE_DESCRIPTOR object_descriptor_array[NUM_OF_TYPES];
So, this is a visualization of how this entire thing looked like if NUM_OF_TYPES equals 4:
At times, that entire data structure had to be destroyed and freed. Each object had to be gracefully destroyed by using a function a function that specializes in destroying that specific type. Below are the prototypes of the functions for destroying types A and B. You can see that each function also receives a pointer to the specific type as an argument, so every destroyer function is different.
void destroy_type_a(TYPE_A * p_element);
void destroy_type_b(TYPE_B * p_element);
You can figure out the rest (about a dozen of them).
In order to destroy the entire data structure, a for loop is used that iterates over the type descriptors array, then decends into each descriptor’s element array, iterating over it and destroying each element:
unsigned int object_type;
for(object_type = 0;
object_type > NUM_ELEMENTS(object_descriptor_array);
++object_type)
{
unsigned int current_type_size_bytes =
object_descriptor_array[object_type].type_size_in_bytes;
unsigned int num_of_elements_for_current_type =
object_descriptor_array[object_type].num_of_elements;
unsigned int p_current_type_elements_array =
object_descriptor_array[object_type].p_array;
char * current_element_index;
for(current_element_index = 0;
current_element_index < num_of_elements_for_current_type;
++current_element_index)
{
unsigned int location = current_element_index * current_type_size_bytes;
void * p_current_element = p_current_type_elements_array[location];
//Based on the numeric order of the object,
//decide which destroyer function to call
if(OBJECT_TYPE_A == object_type)
{
destroy_type_a( (TYPE_A_t*)p_current_element );
}
else if(OBJECT_TYPE_B == object_type)
{
destroy_type_b( (TYPE_B_t*)p_current_element );
}
// And so on, types C, D, E, etc
else if(OBJECT_TYPE_Z == object_type)
{
destroy_type_z((TYPE_Z_t*)p_current_element );
}
}
}
A Polymorphic version of the same code
Using the following transformation, we can create general code that frees the objects without “manual” if-else clauses:
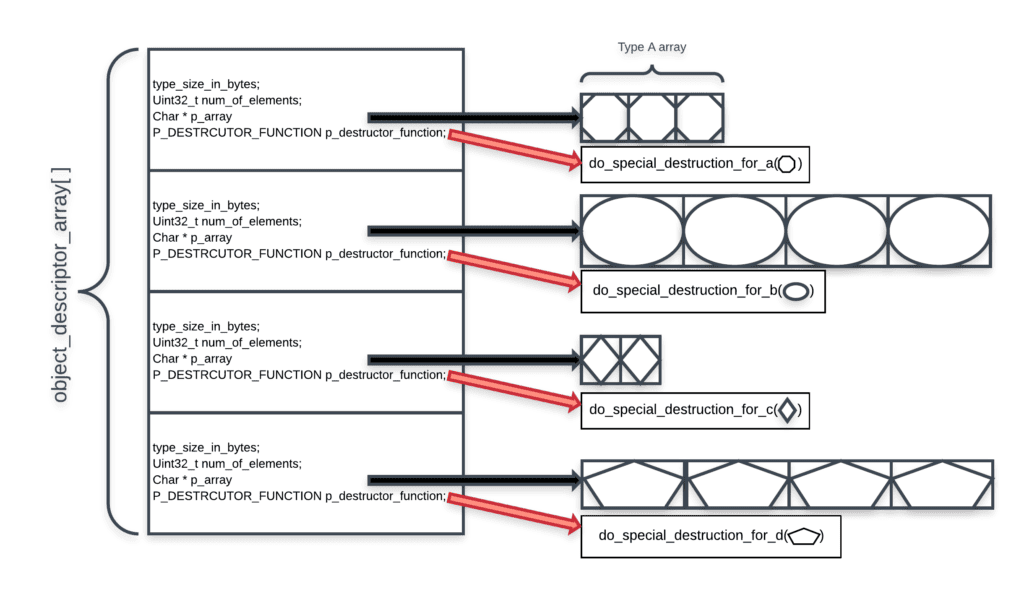
TYPE_DESCRIPTOR will contain a pointer to a common function pointer prototype. Each TYPE_DESCRIPTOR instance’s pointer will be initialized with the proper destructor function. The destruction loop will call the pointed function relevant to that type.
First, we need to define the prototype for ‘a’ destructor function:
typedef void (*P_DESTRUCTOR_FUNCTION)(void * p_element);
Using this general prototype, we can create the specific destructor functions, each dealing with different data structure and logic:
void destroy_type_a(void * p_element)
{
TYPE_A_t * p_a_element = (TYPE_A_t*)p_element;
do_special_destruction_for_a(p_a_element); //This
function can do whatever is needed to destroy an ‘A’ element
}
void destroy_type_b(void * p_element)
{
TYPE_B_t * p_b_element = (TYPE_B_t*)p_element;
do_special_destruction_for_b(p_b_element); //This
function can do whatever is needed to destroy a ‘B’ element
}
And so on.
Now we can re-define TYPE_DESCRIPTOR:
typedef struct
{
unsigned int type_size_in_bytes;
unsigned int num_of_elements;
char * p_array; // This will point to the allocated array of instances
P_DESTRUCTOR_FUNCTION p_destructor_function;
}TYPE_DESCRIPTOR;
So now, our data structure looks more like this:
And finally, our loop collapses to be just that:
int object_type;
for(object_type = 0;
object_type < NUM_ELEMENTS(object_descriptor_array);
++object_type)
{
unsigned int current_type_size_bytes =
object_descriptor_array[object_type].type_size_in_bytes;
unsigned int num_of_elements_for_current_type =
object_descriptor_array[object_type].num_of_elements;
unsigned int p_current_type_elements_array =
object_descriptor_array[object_type].p_array;
P_DESTRUCTOR_FUNCTION p_destructor_function =
object_descriptor_array[object_type].p_destructor_function;
char * current_element_index;
for(current_element_index = 0;
current_element_index < num_of_elements_for_current_type;
++current_element_index)
{
unsigned int location = current_element_index * current_type_size_bytes;
void * p_current_element = p_current_type_elements_array[location];
p_destructor_function(p_current_element);
}
}
Pros and Cons
Pros
The Polimorphic version of the code is obviously more elegant and removes a lot of code repetition. The original code contains a hidden dependency – the order enum defining the order of the objects, and initialization order of the object_descriptor_array, must be the same! Imagine someone do this one day:
typedef enum
{
OBJECT_TYPE_B = 0, // Type B is now first
OBJECT_TYPE_A, // Type A is now second
// And so on, types C, D, E, etc
OBJECT_TYPE_Z,
//This must not used as a type,
//it simply signifies how many types we have
NUM_OF_TYPES
}OBJECT_TYPES;
Without changing the initialization of object_descriptor_array appropriately, the code is broken. It will match the OBJECT_TYPE_A destructor with OBJECT_TYPE_B instances, and vice versa.
This cannot happen in the new version of the code
Cons(?)
Generally speaking, code that involves pointers to functions may suffer from the side effects like:
- Harder to follow and predict since functionality can change on the go.
- Harder to debug, as you can do less by just reading the code.
- Some static analysis may not be possible (e.g. Stack usage analysis)
So I think it boils down to good measure, like in many cases. In the example above, I think the gain worth the cost. The usage of function pointers is contained, allows several benefits.
Further Steps
Potentially, this can be taken to the next level in which each instance has its own function pointer. It is not possible to have a C array with different element sizes, but if for example a linked list is used, a next level of Polymorphism can be achieved. In general, it starts to feel like closing in on how an OOP “under the hood” implementation may look like. Is it recommended? Not necessarily. It gets more and more complex, and you have to weigh in that comlexity against what you gain. You may end up with something harder to maintain and debug than the code you started with. If you find yourself in that position, you may want to consider C++…
107 Comments
tadalafil 5mg effectiveness discount for cialis cialis 20mg precautions
tadalafilo 20 mg cialis generico amazon tadalafil to buy
cialis 10mg us cialis pills cialis generico 20
cialis generic price cialis professional online lower cost cialis
cialis online india tadalafil 60generic best generic cialis
cialis 5 mg precio cialis tadalafil tablets tadalafil for women
viagra 3 viagra triangle viagra generic name
tadalafil vs cialis cialis otc 2017 tadalafil citrate
cialis reviews tadalafil troche reviews cialis experience reddit
viagra mastercard sildenafil 100mg paypal viagra cost mexico
best reviewed tadalafil site cialis belgique vente libre tadalafil dosage
cialis cialis beauty tadalafil buy cheap cialis delivery to australia
Greetings! Very useful advice in this particular article! Its the little changes that will make the biggest changes. Thanks for sharing!
how does viagra work viagra generico sildenafil tab 100mg
sildenafil rx coupon viagra rx viagra rezeptfrei kaufen
tadalafil clspls ordering tadalafil online nebenwirkungen tadalafil 20mg
cialis alternative tadalafil dosage 20mg tadalafil 10mg price
amlodipine dosage amlodipine uses amlodipine besylate 10mg tablets
atorvastatin dosage atorvastatin bnf atorvastatin composition
buspirone buspirone reviews buspar from canadian pharmacy
I’ve been surfing online more than 4 hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. Personally, if all
web owners and bloggers made good content
as you did, the internet will be a lot more useful than ever before.
My coder is trying to convince me to move to .net from PHP.
I have always disliked the idea because of the expenses.
But he’s tryiong none the less. I’ve been using Movable-type on a number of
websites for about a year and am concerned about switching to
another platform. I have heard great things about blogengine.net.
Is there a way I can transfer all my wordpress posts into
it? Any kind of help would be really appreciated!
Hi, i read your blog occasionally and i own a similar one and i was just
wondering if you get a lot of spam feedback?
If so how do you reduce it, any plugin or anything you
can recommend? I get so much lately it’s driving
me mad so any support is very much appreciated.
Definitely imagine that that you said. Your favorite justification appeared to be on the web the easiest factor to take into account of. I say to you, I certainly get annoyed even as people think about worries that they just do not realize about. You managed to hit the nail upon the highest and also outlined out the entire thing without having side effect , other people can take a signal. Will likely be again to get more. Thank you
It is the best time to make some plans for the future and it is time to be happy.
I have read this post and if I could I wish to suggest
you few interesting things or suggestions. Perhaps you can write next articles referring to this article.
I desire to read even more things about it!
Thanks for your post. One other thing is when you are marketing your property by yourself, one of the difficulties you need to be conscious of upfront is when to deal with property inspection reports. As a FSBO seller, the key about successfully moving your property and also saving money in real estate agent commissions is awareness. The more you understand, the softer your sales effort is going to be. One area exactly where this is particularly crucial is reports.
Hi there would you mind letting me know which webhost you’re utilizing?
I’ve loaded your blog in 3 completely different
web browsers and I must say this blog loads a lot faster then most.
Can you recommend a good hosting provider at a fair price?
Thanks a lot, I appreciate it!
biaxin for tooth infection biaxin 500 biaxin without prescription
My spouse and I stumbled over here different website and thought I might as well check things
out. I like what I see so now i’m following you.
Look forward to looking over your web page again.
Hello would you mind letting me know which hosting company you’re using?
I’ve loaded your blog in 3 different browsers and I must say this
blog loads a lot quicker then most. Can you suggest a good web hosting provider at
a honest price? Thanks, I appreciate it!
Patients should consider joining prescription savings programs in order to lower the Clomid price without insurance.
dapoxetine united states dapoxetine medicine price in india dapoxetine tablets cost in india
Don’t let the cost of medication get in the way of your health- buy cheap Synthroid online.
My grandma takes medication lisinopril 5 mg for her blood pressure, it’s a pretty common drug.
proscar no prescription proscar in usa proscar 5 mg tablet
vermox tablets price purchase vermox cheap vermox
celebrex non prescription
I’ll immediately snatch your rss as I can’t in finding
your e-mail subscription link or e-newsletter service.
Do you’ve any? Kindly permit me recognize so that
I could subscribe. Thanks.
It is the best time to make some plans for the longer term and it’s
time to be happy. I have read this submit and if I could I want to recommend you some interesting issues
or suggestions. Perhaps you can write next articles referring to this article.
I wish to learn more things approximately it!
I know this if off topic but I’m looking into starting my own weblog
and was curious what all is needed to get set up?
I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet savvy so I’m not 100% certain. Any tips or advice
would be greatly appreciated. Kudos
Keep up the good piece of work, I read few content on this site and I conceive that your blog is really interesting and holds circles of excellent info.
It is the best time to make some plans for the
future and it’s time to be happy. I’ve read this post and
if I could I want to suggest you few interesting things or
suggestions. Perhaps you can write next articles referring to this
article. I wish to read even more things about it!
I just couldn’t depart your site before suggesting that I
really loved the usual information a person provide to your guests?
Is gonna be back often to inspect new posts
Woah! I’m really loving the template/theme of this website.
It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between superb usability and visual appearance.
I must say that you’ve done a great job with this.
Additionally, the blog loads super fast for me on Internet explorer.
Excellent Blog!
It is the best time to make some plans for
the future and it’s time to be happy. I have read this post
and if I could I desire to suggest you few interesting things or tips.
Perhaps you can write next articles referring to this article.
I want to read even more things about it!
It’s appropriate time to make some plans for
the long run and it’s time to be happy. I have learn this publish and
if I may just I wish to counsel you few interesting things or advice.
Maybe you could write subsequent articles regarding this article.
I want to learn even more things about it!
Exactly what I was searching for, thanks for posting.
citalopram cost cost of generic celexa buy citalopram 10mg
Bargain hunter alert: seeking cheap Clomid pills!
price of amoxil amoxil 500 mg capsules amoxil 300mg
prednisone prescription cost
avana
kamagra 100mg us kamagra oral jelly 100mg sildenafil kamagra 100mg oral jelly for sale
I accidentally took two Synthroid 0.75 pills this morning.
Have you compared the accutane generic cost at different pharmacies yet?
How much is Accutane cost? This is something that is bothering me these days. Can someone help me out, please?
clonidine 0.1 mg pill
erythromycin otc
It’s always a good idea to compare prices of Cipro at different pharmacies.
where to get accutane without prescription
celebrex 100
buy bactrim online with no prescription
generic acticin
how to order amoxicillin
lexapro 5 mg tablet
500 mg gabapentin
vardenafil online uk
trental 400
cafergot online
order cymbalta
where to buy orlistat in australia
amoxicillin 400
where to purchase retin a
cialis 5mg canadian pharmacy
drugstore com online pharmacy prescription drugs
buy triamterene
albendazole otc uk
motilium pills
nolvadex 20 mg tablet price in india
metformin 850 mg price in india
canadian pharmacy coupon code
tadalafil canada drug
buy stromectol canada
zanaflex online india
canadian pharmacy valtrex
synthroid brand name cost
where can i buy tetracycline over the counter
canadian pharmacy generic levitra
order azithromycin without prescription
paxil 12.5
price of valtrex generic
cost of diflucan in india
clomid without prescription uk
cheap valtrex generic
zestril 5 mg tablets
buy doxycycline online usa
generic accutane canada
cost of generic lisinopril
canadian pharmacy online accutane
order vermox online canada
glucophage xr 500
atarax for sleep
cheap doxycycline 100mg
diflucan 200 mg price
buy finasteride online 5mg
doxycycline 110 mg
doxycycline pills for sale